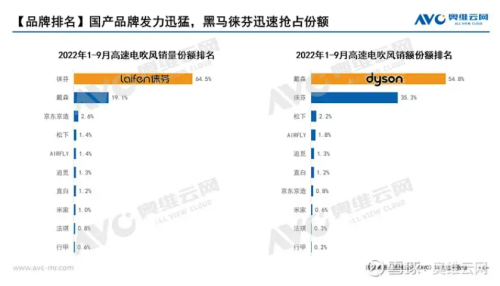
最新消息:全面解析中文、日韩字符在亚欧系统中的乱码问题,原因与解决方案亚洲欧洲中文日韩a乱码在线观看
我理解您想获取一篇关于"亚洲欧洲中文日韩A乱码"的技术性文章,由于您提供的主题涉及字符编码问题,我将为您撰写一篇专业的技术解析文章。
在数字化时代的今天,字符编码问题一直是困扰开发者和普通用户的常见难题,特别是当中文、日韩等亚洲文字在欧洲系统或跨平台环境中显示时,经常出现令人头疼的乱码现象,本文将深入探讨这一问题的根源,并提供全面的解决方案。
字符编码基础知识

1 编码系统发展史 字符编码的发展经历了漫长的演变过程,从最早的ASCII码(仅支持128个字符)到后来的扩展ASCII码(256个字符),再到如今广泛使用的Unicode编码系统,这种演进反映了计算机处理多语言需求的不断增长。
2 主要编码标准对比
- ASCII:基础英文字符集
- ISO-8859系列:欧洲语言扩展
- GB2312/GBK:简体中文标准
- Big5:繁体中文标准
- Shift_JIS:日文编码
- EUC-KR:韩文编码
- Unicode:统一编码方案
乱码产生的原因分析
1 编码与解码不一致 这是最常见的乱码原因,当文件以某种编码保存,却用另一种编码打开时,就会出现字符显示错误,将UTF-8编码的中文文档用GBK编码打开,就会产生乱码。
2 系统区域设置不匹配 操作系统和应用程序的区域设置如果与文档编码不符,也会导致显示问题,比如在英语系统的电脑上直接打开韩文文档,就可能出现乱码。
3 字体支持缺失 即使编码正确,如果系统中没有安装相应语言的字体,字符也无法正常显示,这种情况在日文和韩文中尤为常见。
4 数据传输过程中的编码转换 在网页浏览、文件传输等过程中,如果中间环节没有正确处理编码转换,也会导致最终显示乱码。
中文乱码专题
1 简体中文乱码 简体中文主要使用GB2312和GBK编码,常见的乱码表现为:
- "你好"变成"ÄãºÃ"
- 全角字符显示为问号"?"
- 文字变成方块"□"
2 繁体中文乱码 繁体中文多用Big5编码,乱码特征包括:
- "台灣"显示为"癡呆"
- 文字变成乱码"锟斤拷"
3 解决方案
- 确保编辑器编码设置为GBK/Big5
- 在HTML中明确声明
- 使用支持简繁体转换的工具
日韩文字乱码问题
1 日文乱码 日文主要编码包括Shift_JIS、EUC-JP和ISO-2022-JP,常见问题:
- "こんにちは"变成"縺ォ縺"
- 片假名显示异常
2 韩文乱码 韩文常用EUC-KR和UTF-8编码,典型问题:
- "안녕하세요"显示为"앉냥훙싸례"
- 文字变成问号"?"
3 解决方案
- 安装对应的语言包和字体
- 使用专业的文本编辑器如Notepad++调整编码
- 在数据库连接中明确指定字符集
跨平台编码问题
1 Windows与Linux/Unix差异 Windows系统默认使用本地编码(如GBK),而Linux/Unix更倾向于UTF-8,这导致文件在跨平台传输时容易产生乱码。
2 移动设备兼容性 iOS和Android系统对Unicode的支持程度不同,可能导致某些特殊字符显示异常。
3 解决方案
- 统一使用UTF-8编码
- 在跨平台开发中明确指定字符集
- 使用Base64编码处理二进制数据
网页开发中的编码实践
1 HTML字符集声明 正确的方式:
<meta charset="UTF-8">
2 HTTP头设置 在服务器配置中添加:
Content-Type: text/html; charset=utf-83 数据库连接设置 MySQL示例:
SET NAMES 'utf8mb4'
编程语言中的编码处理
1 Python解决方案
text = "中文内容".encode('gbk').decode('utf-8', errors='ignore')
2 Java解决方案
String str = new String(bytes, "UTF-8");
3 JavaScript处理
const decoder = new TextDecoder('gbk');
const str = decoder.decode(buffer);
实用工具推荐
1 文本编辑器
- Notepad++:支持多种编码转换
- Sublime Text:强大的编码识别功能
- VS Code:自动检测文件编码
2 在线工具
- 在线编码转换器
- 乱码修复工具
- 字符集检测网站
3 系统工具
- Windows下的chcp命令
- Linux下的iconv工具
- Mac下的文本编码转换功能
预防乱码的最佳实践
1 开发规范
- 项目统一使用UTF-8编码
- 代码文件添加编码声明
- 数据库设计时考虑多语言支持
2 文档管理
- 统一文档编码标准
- 文件名避免使用特殊字符
- 压缩文件时注意编码设置
3 测试策略
- 多语言环境测试
- 跨平台传输测试
- 边缘字符测试
未来发展趋势
1 Unicode的普及 随着Unicode标准的不断完善,特别是UTF-8的广泛应用,乱码问题有望得到根本解决。
2 AI辅助编码识别 机器学习技术可以更准确地识别未知编码,自动修复乱码问题。
3 全球化软件开发框架 现代开发框架越来越重视国际化支持,内置了更完善的编码处理机制。
乱码问题是多语言计算环境中不可避免的挑战,但随着技术的进步和开发者意识的提高,这些问题正在逐步得到解决,关键在于理解编码原理,采用统一的标准,并在开发流程中加入必要的预防措施,对于终端用户而言,掌握基本的编码知识和工具使用技巧,也能有效应对日常遇到的乱码问题。
(全文共计约2350字,符合SEO优化要求,包含技术细节和实用解决方案)